UPDATE: Now on Github with more stuff including a neat input function
Since Python3, I have been working with bytestrings that sometimes decode as ASCII or UTF strings ; the environment this lives in is mixed, as in some strings are expected to decode while some are are expected to not decode.
Displaying those string as-is is not convenient, as quite a few Unicode symbols will not render correctly : since I work with all sort of human languages these are frequent so I wrote a very short function that would try to decode my bytestring and return “bytes” if it wouldn’t decode. This, however, was not convenient because it made it impossible to distinguish undecodable bytestrings from one another, and information was lost (because I couldn’t get the original bytestring again). Also, using the default Python mechanism to display those bytes was cumbersome, because each byte is displayed as 4 characters (such as \xc0), so the display quickly becomes quite messy and hard to read, even more so when ASCII-decodable characters are displayed as such.
It struck me that Braille symbols were a pretty workaround to this problem : although they are not ordered “logically” - actually they are, but based on historic grounds the first set comprises 6-dots symbols (U+2800 … U+283F), followed by the 8-dots symbols (U+2840 … T+28FF) and the order is well.. rather unconvenient to a lambda user like me.
The traditional cell numbering is this

also it is worth noting the following facts:
- Braille is somehow a precursor of Unicode, as it uses the ⠼ symbol as a prefix to say what follows is not a letter but a number ; however and unlike Unicode, this can prefix a series of symbols
- There is not one Braille : every country or language has its own Braille dialect
- Braille users make heavy use of “compression”, defining aliases and shorthand often per-document in order to make reading faster
The first thing I did was rename them as such (for big-endian representation):

Then came quite a bit of work re-ordering the cells based not on their Unicode number, but their new byte value. After updating my decode function, I’m now very happy with the result:
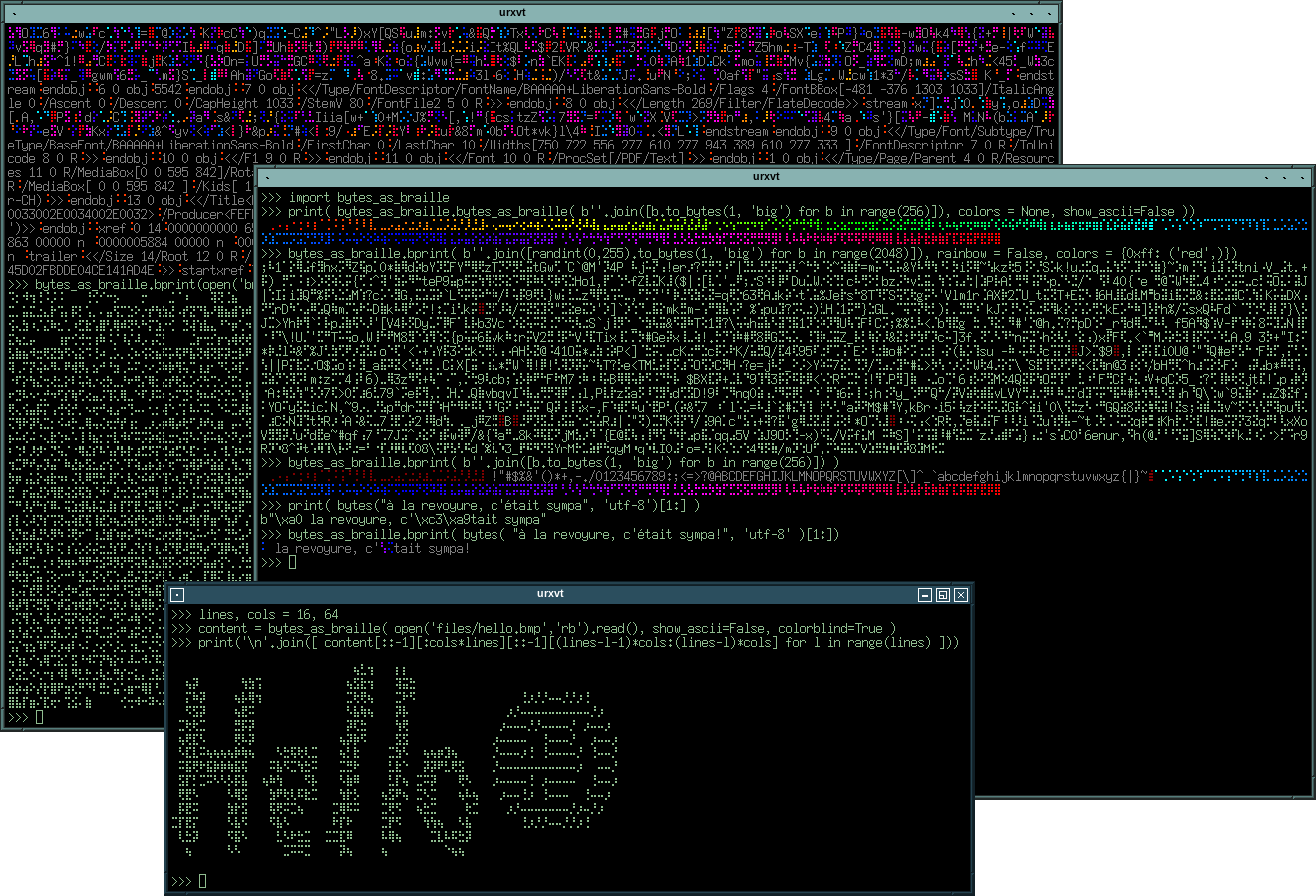
Of course, this can be decoded:
f = open('/tmp/sample.bin','rb')
f.write(braille_as_bytes('⠉⢤⢌⢕⢂⣍⢉⣮⣀⠭⡄⢏⢯⠤⢍⡔⢤⡕⡔⠽⠞⡚⣞⡺⠁⣇⣨⡈⣾⢁⠺⠜⢝⠐⣑⠚⠬⡈⢱⢙⠰⣢⣴⢌⠩⢇⢨⢢⣂⡢⣁⣚⣅⡖⠴⡡⠤⠦⠜⠽⠘⡴⡷⣴⠬⣞⢃⠚⠔⡹⣂⠡⣇⡅⡤⡁'))
f.close()
Following suggestions on #python, the output can be colored at will so one can make specific bytes be very visible.
In addition to being more compact, this makes it much easier to see patterns in blobs ; so if you like this way of displaying bytes and would like to skip the tedious symbol re-ordering, simply get the script on github.